让我们现在用一个简单的例子使这些想法具体化。我们考虑一个模型
一维线性回归模型
一维线性回归模型将输入
该模型有两个参数
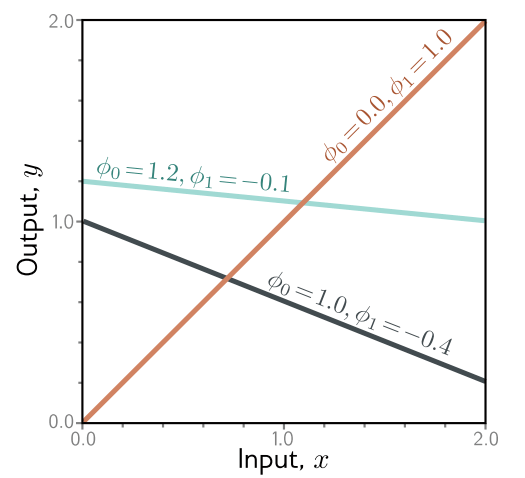
图 2.1 线性回归模型。对于给定的参数选择 ϕ = [ϕ₀, ϕ₁],该模型根据输入(x轴)对输出(y轴)做出预测。y轴截距 ϕ₀ 和斜率 ϕ₁ 的不同选择会改变这些预测(青色、橙色和灰色线条)。线性回归模型(方程2.4)定义了一系列输入/输出关系(线条),而参数决定了家族中的成员(特定的线条)。(交互式演示)
损失
对于这个模型,训练数据集(图2.2a)包含
模型预测
由于最佳参数会最小化这个表达式,我们称之为最小二乘损失。平方运算意味着偏差的方向(即,直线是否在数据的上方或下方)不重要。对此选择也有理论上的原因,我们将在第5章中回到这个问题。
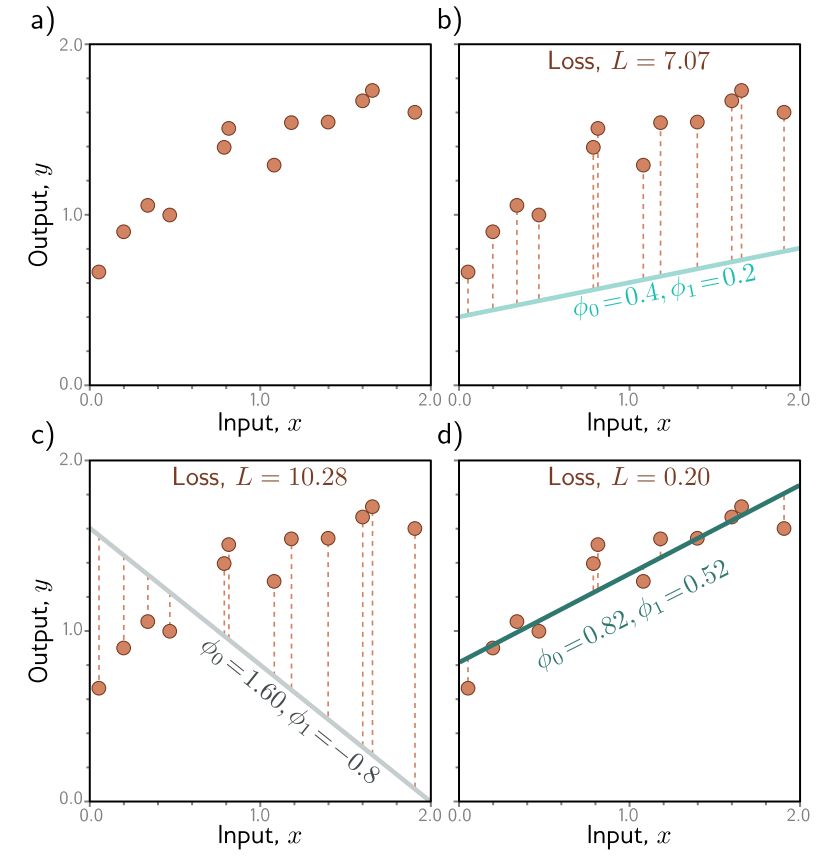
图 2.2 线性回归训练数据、模型和损失。a) 训练数据(橙色点)包含 I = 12 个输入/输出对 {xᵢ, yᵢ}。b–d) 每个面板显示了具有不同参数的线性回归模型。根据 y 轴截距和斜率参数 ϕ = [ϕ₀, ϕ₁] 的选择,模型误差(橙色虚线)可能会更大或更小。损失 L 是这些误差平方的总和。定义面板 (b) 和 (c) 中直线的参数的损失 L 分别为 7.07 和 10.28,因为这些模型拟合得不好。面板 (d) 中的损失 L= 0.20 较小,因为模型拟合得好;实际上,这是所有可能直线中最小的损失,所以这些是最优参数。(交互式演示)
损失
只有两个参数(y轴截距
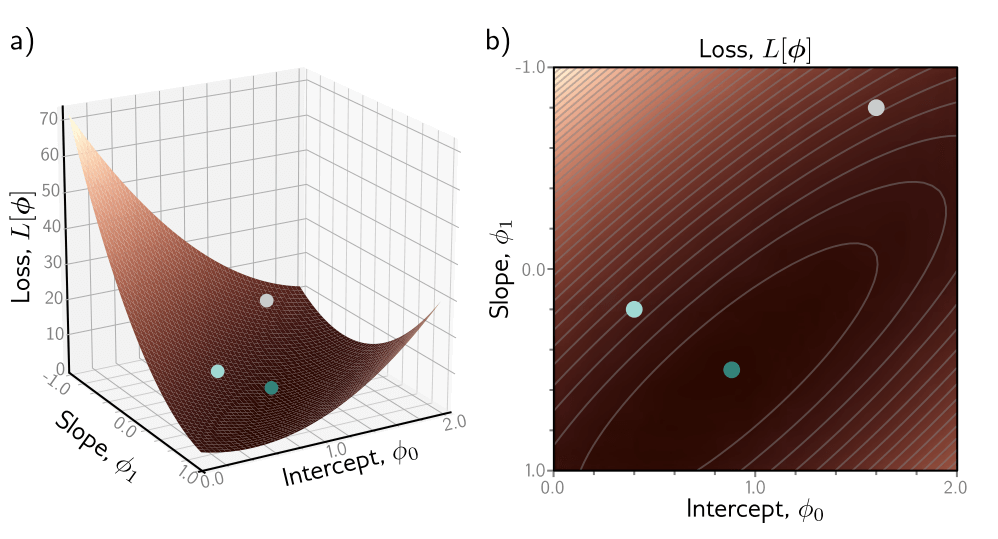
图 2.3 线性回归模型的损失函数与图2.2a中的数据集。a) 参数组合ϕ = [ϕ₀, ϕ₁]的每一个组合都有一个相关的损失。结果损失函数L[ϕ]可以可视化为一个表面。三个圆圈代表图2.2b-d中的线条。b) 损失也可以可视化为热图,其中更亮的区域代表更大的损失;这里我们是从(a)中的表面正上方直接向下看,灰色椭圆代表等高线。最佳拟合线(图2.2d)具有最小损失的参数(绿色圆圈)。
训练
寻找最小化损失的参数的过程被称为模型拟合、训练或学习。基本方法是随机选择初始参数,然后通过“沿着”损失函数“向下走”来改进它们,直到我们到达底部(图2.4)。一种方法是测量当前位置表面的梯度,并朝最陡峭的下坡方向迈出一步。然后我们重复这个过程,直到梯度变平,我们无法进一步改进 [1]。
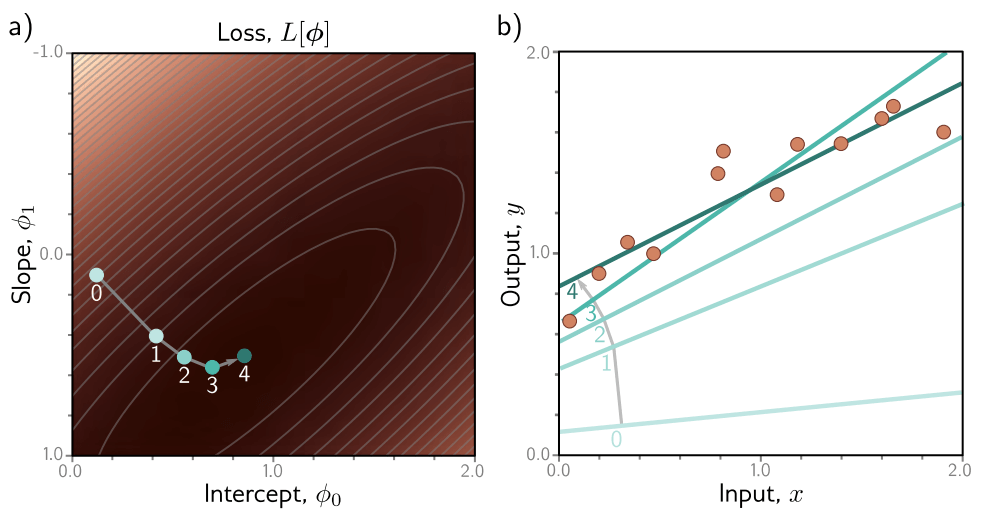
图 2.4 线性回归训练。目标是找到对应于最小损失的y轴截距和斜率参数。a) 迭代训练算法随机初始化参数,然后通过“下山”来改进它们,直到无法进一步改进。这里,我们从位置0开始,向下移动一定距离(垂直于等高线)到位置1。然后我们重新计算下山方向并移动到位置2。最终,我们到达函数的最小值(位置4)。b) 面板(a)中的每个位置0-4对应于不同的y轴截距和斜率,因此代表不同的直线。随着损失的减少,这些直线更紧密地拟合数据。(交互式演示)
注
[1] 这种迭代方法对于线性回归模型实际上是不必要的。在这里,可以找到参数的封闭形式表达式。然而,这种梯度下降方法适用于更复杂的模型,这些模型没有封闭形式的解决方案,并且参数太多,无法评估每种值组合的损失。
测试
训练好模型后,我们想知道它在现实世界中的表现如何。我们通过在独立的测试数据集上计算损失来做到这一点。预测准确性在多大程度上推广到测试数据,部分取决于训练数据的代表性和完整性。然而,它也取决于模型的表达能力。像直线这样的简单模型可能无法捕捉输入和输出之间的真实关系。这被称为欠拟合。相反,一个非常有表现力的模型可能会描述训练数据中的统计特性,这些特性是非典型的,并导致不寻常的预测。这被称为过拟合。