从输入数据构建模型而无需对应的输出标签的过程称为无监督学习;由于缺乏输出标签,也就不存在所谓的“监督”。与监督学习不同的是,目标不是学习从输入到输出的映射,而是描述或理解数据的结构。和监督学习一样,数据可能具有非常不同的特征:可能是离散的或连续的、低维的或高维的,以及恒定长度或可变长度的。
生成式模型
本书主要介绍生成式无监督模型,这些模型通过学习合成新的数据示例,这些示例在统计上与训练数据无异。有些生成模型明确描述了输入数据的概率分布,新示例就是从这个分布中采样生成的。另一些模型只是学习生成新示例的机制,而不明确描述其分布。
最先进的生成模型能够合成出极其逼真但与训练样本不同的实例。它们特别成功地用于生成图像(如图1.5)和文本(如图1.6)。此外,这些模型还可以在某些输出已预先确定的条件下生成数据(称为条件生成)。例如包括图像修补(如图1.7)和文本补全(如图1.8)。 确实,现代的文本生成模型如此强大,以至于它们看起来非常智能。给定一段文字,然后是一个问题,模型通常可以通过生成文档中最可能的完整内容来 “填补”缺失的答案。但实际上,模型只知道语言的统计数据,并不了解其答案的意义。

图 1.5 生成图像的模型。左:这两幅图像是基于训练集包含猫的照片的模型生成的。它们并不是真实的猫,而是概率模型中的样本。右:这两幅图像是基于训练集包含建筑物照片的模型生成的。改编自Karras等人(2020b)[1]。

图 1.6 由文本数据的生成模型合成的短篇小说。该模型描述了一个概率分布,为每个输出字符串分配一个概率。从模型中采样创建的字符串遵循训练数据(这里是短篇小说)的统计规律,但以前从未见过。

图 1.7 修复。在原始图像(左)中,男孩被金属电缆遮挡。这些不需要的区域(中)被移除,生成模型在剩余像素必须保持不变的约束下合成新图像(右)。改编自Saharia等人(2022a)[2]。

图 1.8条件文本合成。给定一个初始文本(黑色部分),文本生成模型可以通过合成字符串的“缺失”剩余部分来合理地继续生成字符串。由 GPT3(Brown 等人,2020 年)[3] 生成。

图 1.9人脸的变化。人的面部大约包含42块肌肉,因此只需42个数字就可以描述同一人在相同光照条件下图像中的大部分变化。一般来说,图像、音乐和文本的数据集可以通过相对较少的潜变量来描述,尽管将这些变量与特定的物理机制联系起来通常更加困难。图像来自动态面部数据库(Holland等人,2019年)[4]。
潜变量
有些(但不是全部)生成模型利用了这样一个事实:数据的维度可能低于观察到的变量数量所暗示的维度。例如,有效且有意义的英语句子数量远小于随机抽取单词所能创建的字符串数量。同样,现实世界中的图像只是通过为每个像素随机绘制红色、绿色和蓝色(RGB)值所能创建的图像中的一小部分。这是因为图像是由物理过程生成的(见图1.9)。
这导致了一个想法,即我们可以使用较少数量的潜变量来描述每个数据示例。在这里,深度学习的作用是描述这些潜变量与数据之间的映射。潜变量通常具有一个简单的通过设计得到的概率分布。通过从该分布中采样并将结果传递给深度学习模型,我们可以创建新的样本(图 1.10)。
这些模型带来了处理真实数据的新方法。例如,我们可以找出两个真实例子的潜变量。我们可以通过对这些实例的潜在表示进行插值,并将中间位置映射回数据空间(图 1.11)。
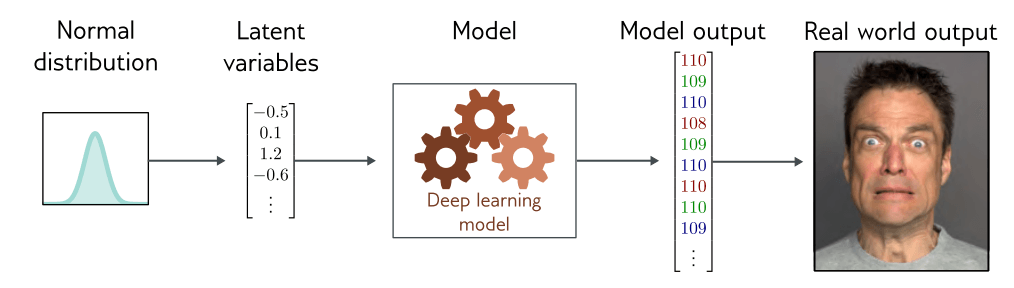
图 1.10潜变量。许多生成模型使用深度学习模型来描述低维“隐”变量与观测到的高维数据之间的关系。潜变量在设计上具有简单的概率分布。因此,可以通过从潜变量的简单分布中采样,然后使用深度学习模型将样本映射到观测数据空间来生成新的示例。

图 1.11 图像插值。在每一行中,左右两边的图像是真实的,而中间的三幅图像代表由生成模型创建的一系列插值。支撑这些插值的生成模型已经学会,所有图像都可以通过一组潜变量来创建。通过找到这两幅真实图像的这些变量,插值它们的值,然后使用这些中间变量来创建新图像,我们可以生成既视觉上合理又混合了两个原始图像特征的中间结果。顶部行改编自Sauer等人(2022年)[5]。底部行改编自Ramesh等人(2022年)[6]。
连接监督学习和无监督学习
具有潜变量的生成模型也可以受益于输出具有结构的监督学习模型(图1.4)。例如,考虑学习预测与标题相对应的图像。我们可以学习解释文本的潜变量与解释图像的潜变量之间的关系,而不是直接将文本输入映射到图像。
这有三个优点。首先,由于输入和输出的维度较低,我们现在可能需要更少的文本/图像对来学习这种映射。其次,我们更有可能生成一张看起来合理的图像;任何合理的潜变量值都应该产生一个看起来像合理例子的东西。第三,如果我们在两组潜变量之间的映射或从潜变量到图像的映射中引入随机性,那么我们可以生成多张图像,这些图像都可以用标题很好地描述(图 1.12)。

图 1.12 根据标题“时代广场上滑滑板的泰迪熊”生成的多个图像。由DALL·E-2(Ramesh等人,2022年)生成。[6]
注
[1] Karras, T., Aila, T., Laine, S., & Lehtinen, J. (2018). Progressive growing of GANs for im-proved quality, stability, and variation. Inter-national Conference on Learning Representa-tions.
[2] Saharia, C., Chan, W., Chang, H., Lee, C., Ho, J., Salimans, T., Fleet, D., & Norouzi, M. (2022a). Palette: Image-to-image diffusion models. ACM SIGGRAPH.
[3] Brown, T., Mann, B., Ryder, N., Subbiah, M., Kaplan, J. D., Dhariwal, P., Neelakantan, A., Shyam, P., Sastry, G., Askell, A., et al. (2020). Language models are few-shot learners. Neu-ral Information Processing Systems, 33, 1877– 1901.
[4] Holland, C. A., Ebner, N. C., Lin, T., & Samanez-Larkin, G. R. (2019). Emotion identifica-tion across adulthood using the dynamic faces database of emotional expressions in younger, middle aged, and older adults. Cognition and Emotion, 33(2), 245–257.
[5] Sauer, A., Schwarz, K., & Geiger, A. (2022). StyleGAN-XL: Scaling StyleGAN to large di-verse datasets. ACM SIGGRAPH.
[6] Ramesh, A., Dhariwal, P., Nichol, A., Chu, C., & Chen, M. (2022). Hierarchical text-conditional image generation with CLIP la-tents. arXiv:2204.06125.