机器学习的最后一个领域是强化学习。这一范式引入了一个智能体的概念,它生活在一个世界中,并且可以在每个时间步骤执行某些动作。这些动作会改变系统的状态,但不一定是确定性的。执行动作也会产生奖励,而强化学习的目标是让智能体学会选择那些能够在平均意义上获得高奖励的动作。
一个复杂的问题是,奖励可能在执行动作之后的一段时间才会出现,因此将奖励与动作关联并不是一件简单的事情。这就是所谓的时间信用分配问题。在学习过程中,智能体必须在探索和利用已知信息之间做出权衡;也许智能体已经学会了如何获得适度的奖励;它是应该遵循这个策略(利用已知信息),还是应该尝试不同的动作来看看是否能够改进(探索其他机会)?
两个例子
考虑教一个仿人机器人进行移动。该机器人在给定时间内可以执行有限数量的动作(移动各个关节),这些动作会改变世界的状态(它的姿态)。我们可能会因为机器人在障碍赛中到达检查点而给予奖励。为了到达每个检查点,它必须执行许多动作,而当它收到奖励时,哪些动作对此有贡献,哪些是无关的,这是不明确的。这就是时间信用分配问题的一个例子。
第二个例子是学习下棋。同样,智能体在任何给定时间都有一组有效动作(棋步)。然而,这些动作以一种非确定性的方式改变系统的状态;对于任何选择的动作,对手可能会以许多不同的走法回应。在这里,我们可以基于捕获棋子来设置奖励结构,或者只是在游戏结束时为获胜设定单一奖励。在后一种情况下,时间信用分配问题是极端的;系统必须学习它所做的许多走法中哪些对成功或失败起到了关键作用。
探索-利用权衡在这两个例子中也很明显。机器人可能已经发现,它可以通过侧躺并用一条腿推动来取得进展。这种策略会使机器人移动并产生奖励,但比最优解(即平衡双腿行走)要慢得多。因此,它面临着在利用已知知识(如何笨拙地沿地面滑动)和探索动作空间(可能会带来更快的运动)之间的选择。同样,在国际象棋的例子中,智能体可能学到了一个合理的开局序列。它应该利用这些知识还是探索不同的开局序列?
深度学习如何融入强化学习框架也许并不明显。有几种可能的方法,但其中一种技术是利用深度网络建立从观察到的世界状态到行动的映射。这就是所谓的策略网络。在机器人示例中,策略网络将学习从传感器测量到关节运动的映射。在国际象棋的示例中,网络将学习从棋盘当前状态到棋步选择的映射(图 1.13)。
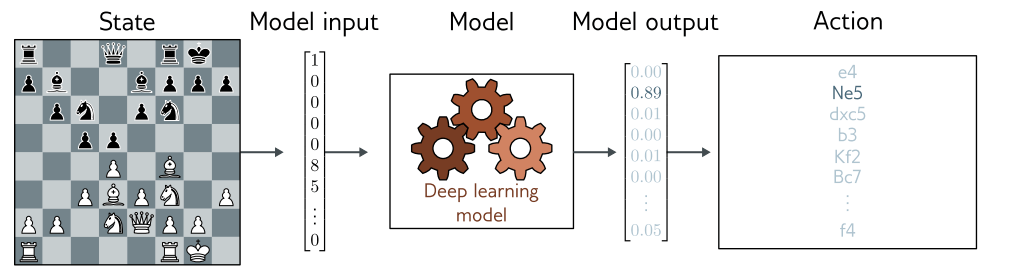
图 1.13 强化学习中的策略网络。将深度神经网络融入强化学习的一种方法是使用它们来定义从状态(这里是棋盘上的位置)到动作(可能的走法)的映射。这种映射被称为策略。