监督学习模型定义了从输入数据到输出预测的映射。 在接下来的部分中,我们将讨论输入、输出、模型本身以及“训练”模型的含义。
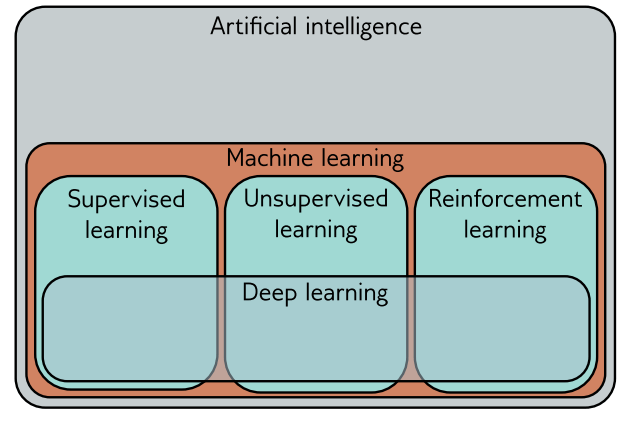
图 1.1 机器学习是人工智能的一个领域,将数学模型拟合到观测数据上。它可以粗略地分为监督学习、无监督学习和强化学习。深度神经网络对这些领域都有贡献。
回归和分类问题
图 1.2 描述了几个回归和分类问题。在每种情况下,都有一个有意义的现实世界输入(一个句子、一个声音文件、一幅图像等),并将其编码为一个数字向量。这个向量构成了模型输入。模型将输入映射到输出向量,然后将输出向量 “翻译”回有意义的现实世界预测。现在,我们将重点放在输入和输出上,并将模型视为一个黑盒子,它接收一个数字向量并返回另一个数字向量。
图1.2a中的模型根据诸如面积和卧室数量等输入特征预测房屋价格。这是一个回归问题,因为该模型返回的是一个连续数值(而不是类别标签)。相比之下,图1.2b中的模型以分子的化学结构为输入,并预测其熔点和沸点。这是一个多元回归问题,因为它预测了多个数值。
图1.2c中的模型接收包含餐厅评价的文本字符串作为输入,并预测该评价是正面还是负面。这是一个二元分类问题,因为模型试图将输入分配到两个类别之一。输出向量包含了输入属于每个类别的概率。图1.2d和1.2e展示了多分类问题。在这里,模型将输入分配到N > 2个类别中的一个。在图1.2d中,输入是一个音频文件,模型预测其中包含哪种音乐类型;在图1.2e中,输入是一张图片,模型预测其中包含哪个对象。在每种情况下,模型返回一个大小为N的向量,包含了N个类别的概率。
输入
图 1.2 中的输入数据差异很大。在房屋定价示例中,输入是一个包含能够表征房产属性值的固定长度向量。这属于表格数据的一个例子,因为这些数据没有内部结构;如果我们改变输入的顺序并构建一个新的模型,我们预期模型预测结果保持不变。
相反,在餐馆评论的例子中,输入是一段文本。这段文本的长度可能会根据评论中的单词数量而变化,此处顺序很重要;我妻子吃了鸡肉(my wife ate the chicken)和我妻子被鸡吃(the chicken ate my wife)是不一样的。在将文本传递给模型之前,必须将其编码为数值形式。这里,我们使用一个大小为10,000的固定词汇表,并简单地连接单词索引。
对于音乐分类的例子,输入向量可能具有固定大小(例如10秒的音频片段),但其维度非常高(即包含很多值)。数字音频通常以44.1 kHz的采样率进行采样,并由16位整数表示,因此10秒的片段包含441,000个整数值。显然,监督学习模型必须能够处理较大的输入量。在图像分类的例子中(其输入是由每个像素处的RGB值拼接而成),输入也同样庞大。此外,它还包含空间结构;上下相邻的两个像素即使在输入向量中不相邻,它们之间也密切相关。
最后,考虑用于预测分子的凝固点和沸点的模型所需的输入。一个分子可能包含不同数量的原子,这些原子可以以不同的方式连接。在这种情况下,模型必须同时摄入分子的几何结构及其构成原子。
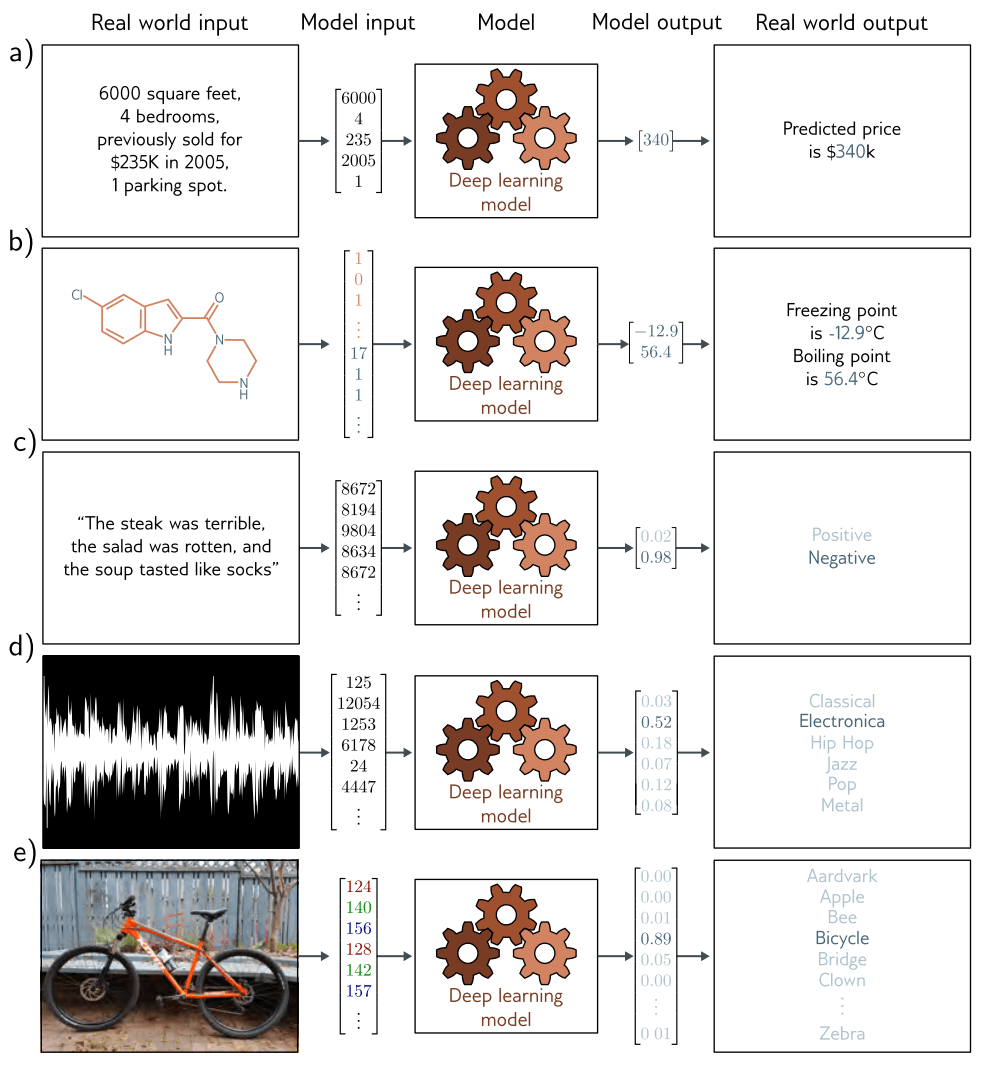
图 1.2 回归和分类问题。a) 这个回归模型接受描述某个属性的一组数字,并预测其价格。b) 这个多元回归模型接受化学分子的结构信息,并预测其熔点和沸点。c) 这个二元分类模型接受一家餐馆的评论,并将其归类为正面或负面。d) 这个多类别分类问题将音频片段分配给N种流派之一。e) 另一个多类别分类问题是根据图像中可能包含的N种不同物体对图像进行分类。
机器学习模型
直到现在,我们一直将机器学习模型视为一个黑盒,它接受一个输入向量并返回一个输出向量。但这个黑盒里究竟有什么?考虑这样一个模型:根据孩子的年龄预测其身高(图1.3)。机器学习模型是一个数学方程,用于描述平均身高如何随年龄变化(图1.3中的青色曲线)。当我们通过运行这个方程输入年龄时,它会返回相应的身高。例如,如果年龄是10岁,那么我们预测身高的值将是139厘米。
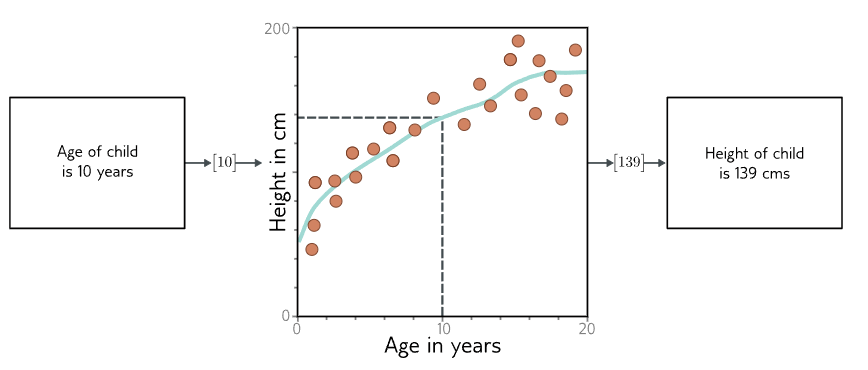
图 1.3 机器学习模型。该模型表示一组关系,将输入(孩子的年龄)与输出(孩子的身高)联系起来。特定的关系是通过训练数据选择的,这些数据由输入/输出对(橙色点)组成。当我们训练模型时,我们会在可能的关系中搜索一个能够很好地描述数据的关系。在这里,经过训练的模型是青色曲线,并可以用于计算任何年龄下的身高。
更精确地说,该模型表示一个方程族,将输入映射到输出(即不同青色曲线)。特定的方程(曲线)是通过使用训练数据(输入/输出配对的例子)来选择的。在图1.3中,这些配对由橙色点表示,并且我们可以看到该模型(青色线)能够合理地描述这些数据。当我们提到训练或拟合一个模型时,我们是指在所有可能的方程族(可能的不同青色曲线)中寻找一个最准确描述训练数据的那个。
因此,图1.2中的模型需要带有标签的输入/输出对来进行训练。例如,音乐分类模型需要大量的音频片段,其中人类专家已经标识出了每段音频的类型。这些输入/输出对在训练过程中扮演了教师或监督者的角色,这导致了“监督学习”这一术语的产生。
深度神经网络
本书涉及深度神经网络,这是一种特别有用的机器学习模型。它可以表示输入和输出之间极其广泛关系的方程组,而且在这个方程组中搜索描述训练数据的关系特别容易。
深度神经网络可以处理非常大的,长度可变的输入,并且这些输入包含各种内部结构。它们可以输出单一数值(回归)、多个数值(多元回归),或者两个或多个类别的概率(分别对应二分类和多分类)。正如我们将在下一节看到的,其输出也可能非常大,长度可变并且包含内部结构。现在可能很难想象具有这些性质的方程,读者因暂时搁置怀疑。
结构化输出
图1.4a展示了一种用于语义分割的多变量二分类模型。在这里,输入图像中的每个像素都被分配了一个二分类标签,以指示该像素是否属于牛或背景。图1.4b展示了多变量回归模型,在这种情况下,输入是一个街道场景的图像,输出是每个像素处的深度值。在这两种情况下,输出都是高维且结构化的。然而,这种结构与输入紧密相关,可以被利用;如果一个像素被标记为“牛”,那么具有相似RGB值的邻近像素很可能也有相同的标签。
图1.4c–e展示了三个模型,在这些模型中,输出具有较为复杂的结构,并不紧密依赖于输入。图1.4c展示了一个模型,其中输入是音频文件,输出是从该文件中转录的单词。图1.4d 是一个翻译模型,输入是一段英文文本,输出则是法语翻译。图1.4e 描述了一个非常具有挑战性的任务,在此任务中,输入是描述性文本,而模型必须生成一张与该描述相符的图像。
原则上,后三个任务可以在标准监督学习框架中解决,但由于以下两个原因,它们更加困难。首先,输出可能是模糊的;一个英语句子可以有多个有效的法语翻译,并且与任何描述兼容的图像也有多个。其次,输出包含相当复杂的结构;并非所有单词序列都能构成有效的英法句子,也不是所有 RGB 值集合都能生成可信的图像。除了学习映射之外,我们还需要尊重“输出”的“语法”。
幸运的是,这种“语法”可以在不需要输出标签的情况下学习。例如,我们可以通过学习大量文本数据的统计特征来学会如何形成有效的英文句子。这为本书的下一部分提供了联系,下一部分将讨论无监督学习模型。
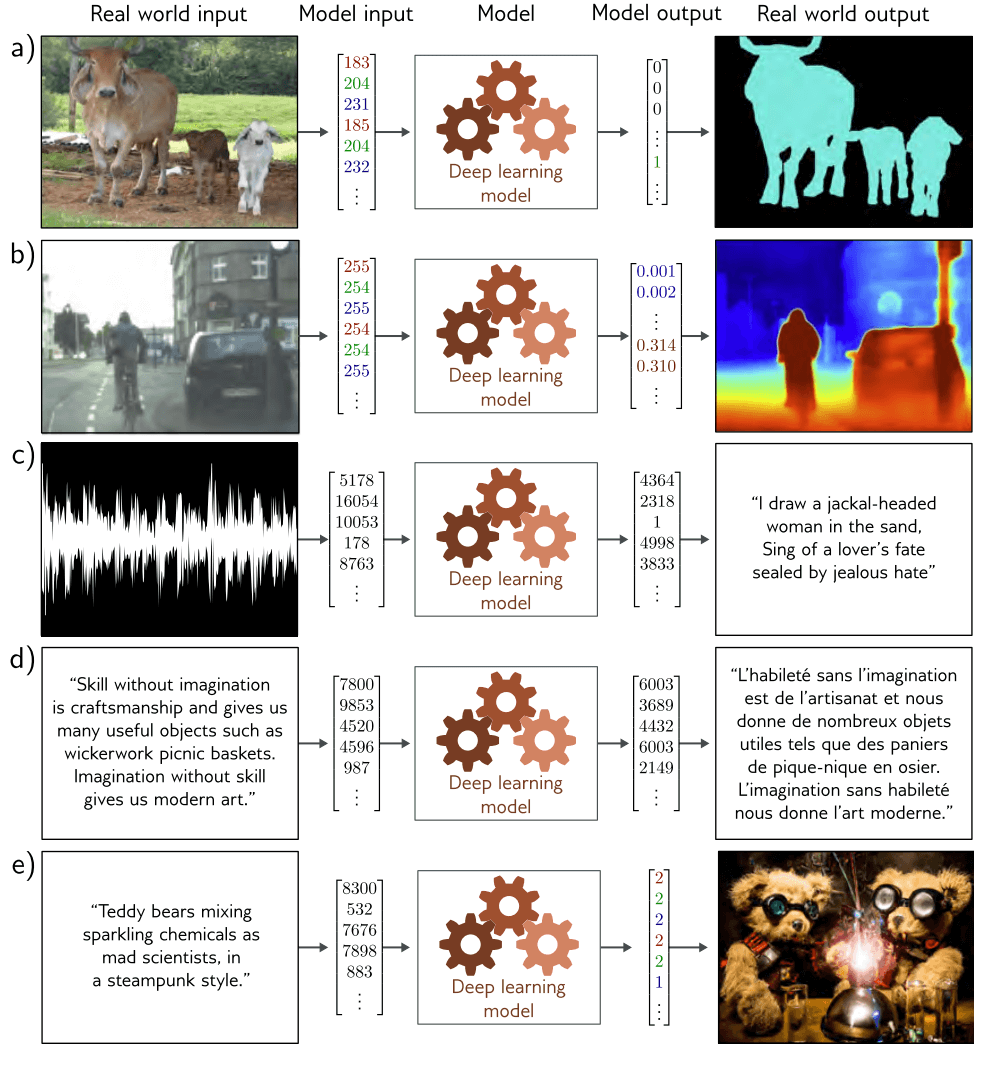
图 1.4 监督学习中的结构化输出任务。a) 这种语义分割模型将RGB图像映射为一个二值图像,表示每个像素是否属于背景或牛(参考Noh等,2015)[1]。 b) 这种单目深度估计模型将RGB图像映射到一个输出图像,其中每个像素代表该点的深度(参考Cordts等,2016)[2]。 c) 这种音频转录模型将音频样本映射为其所含语音文字的转录。 d) 这种翻译模型将英语文本字符串映射为它的法语翻译。 e) 这种图像生成模型将一个描述映射为一幅图像(示例来自https://openai.com/dall-e-2/)。在每种情况下,输出具有复杂的内部结构或语法。有时,多个输出都与输入兼容。
注
[1] Noh, H., Hong, S., & Han, B. (2015). Learning deconvolution network for semantic segmenta- tion.IEEE International Conference on Com- puter Vision, 1520–1528.
[2] Cordts, M., Omran, M., Ramos, S., Rehfeld, T., Enzweiler, M., Benenson, R., Franke, U., Roth, S., & Schiele, B. (2016). The Cityscapes dataset for semantic urban scene understand- ing.IEEE/CVF Computer Vision & Pattern Recognition, 1877–1901